



Why and how to fine-tune GPT models

Hey — It’s Hussein 👋
A bit of a warning today: we are going to get technical…
Our topic is why and how you can fine-tune an LLM model like GPT 4 to fit your business needs, voice, style, and more.
First, a note from this week’s sponsor:

Your info is on the dark web
Every day, data brokers profit from your sensitive info—phone number, DOB, SSN—selling it to the highest bidder. And who’s buying it? Best case: companies target you with ads. Worst case: scammers and identity thieves.
It's time you check out Incogni. It scrubs your personal data from the web, confronting the world’s data brokers on your behalf. And unlike other services, Incogni helps remove your sensitive information from all broker types, including those tricky People Search Sites.
Help protect yourself from identity theft, spam calls, ID theft and health insurers raising your rates. Plus, just for our readers: Get 55% off Incogni using code PRIVACY.
What is fine-tuning?
A bit of background. If you are a user of LLM models like Gemini by Google or GPT 4 by OpenAI, you have a few tools at your disposal to help get results that are better suited for your use case and style.
Prompt Engineering
Few-shots training
Embedding
Fine-tuning
I’ve covered prompt engineering a few times. This is basically the practice of tweaking your prompt to get better results to fit your needs. If you look back through previous issues of GPT Hacks, you’ll find several articles on how to modify your prompt to get better results. Most of these could be considered prompt engineering.
In your prompt design, you can give the LLM a few examples of system, user, and assistant messages that can help train the model in a very small context. This is considered few-shots training. The challenge with this approach is you can use a high number of tokens in your prompt which will be costly and also eat up how much context the LLM has of your conversation.
Embedding is a way to give the LLM more knowledge. The most common use case we’ve seen so far is embedding your company’s help files so that the LLM can better answer customer (or internal service reps) questions about your products and services.
Fine-tuning is a bit more complex than the rest and involves giving the LLM multiple records of conversations that include a system prompt, a user message, and an assistant message. These examples will then be used to train the model on how to respond to your requests better going forward.
Let’s unpack this.
PS: Today's focus is on the backend of ChatGPT, the GPT modes. Which is why I did not include ChatGPT Custom Instructions in the list above. Custom Instructions, in a way, is adding a system prompt to your conversations with ChatGPT.
Why fine-tune GPT?
There are a few reasons:
You are looking for a specific style, tone, or format in your response. We will use an example of this next so you can see it in action.
You want to reduce costs, which can happen in 2 ways:
You fine-tune GPT 3.5 to work for your use case and downgrade from GPT 4.
You fine-tune the model with your system prompt and examples so that you don’t have to send them with each request, saving you tokens and costs.
Improve accuracy on specific tasks and requests that you use often.
Increase the speed of the LLM. If the model is fine-tuned for a specific use case, it will respond faster to requests that match the use case.
Data privacy: You can fine-tune a model so that it does not share any sensitive data that users may have sent to the model or teach it how to handle that data appropriately.
Mitigate training bias: you can train the model with a data set that can help reduce bias in responses.
Adhere to compliance and legal requirements that your app or company has to follow, which might not be part of the LLM’s current knowledge set.
What does fine-tuning training data look like?
Training data is a series of JSON objects that you submit to OpenAI via their dashboard in a .jsonl file.
There are three parts to each row:
A system prompt that gives the LLM a role and sets the context for the LLM to give you relevant results.
A user message which is an example prompt that a user might enter.
An assistant message which is an example response from the LLM.
Here is a quick example from OpenAI:
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}By providing this series of examples, you will train the model on how to respond to user requests.
Keep in mind:
OpenAI requires a minimum of 10 examples.
OpenAI recommends at least 50 examples.
From my testing, around 100-150 seems to be a good dataset.
Remember to include edge cases. For example, when you want the LLM not to give an answer.
How to fine-tune and use your own model?
1. Prepare your training data
The first step is to create your dataset using the sample above.
To simplify this process, I created a sample fine-tuning template you can use that will take 3 CSV columns for the system, user, and assistant prompt and format them in the expected format by OpenAI.
✨ Pro Tip: use this JSON Lines Validator to confirm that your file is in the right format.
2. Upload the .jsonl training file to OpenAI
Head over to the Fine-Tuning section of the OpenAI dashboard.
Click on Create
Choose a model. The current recommended model is gpt-3.5-turbo-1106
Upload your file
Follow the prompts to start the fine-tuning training
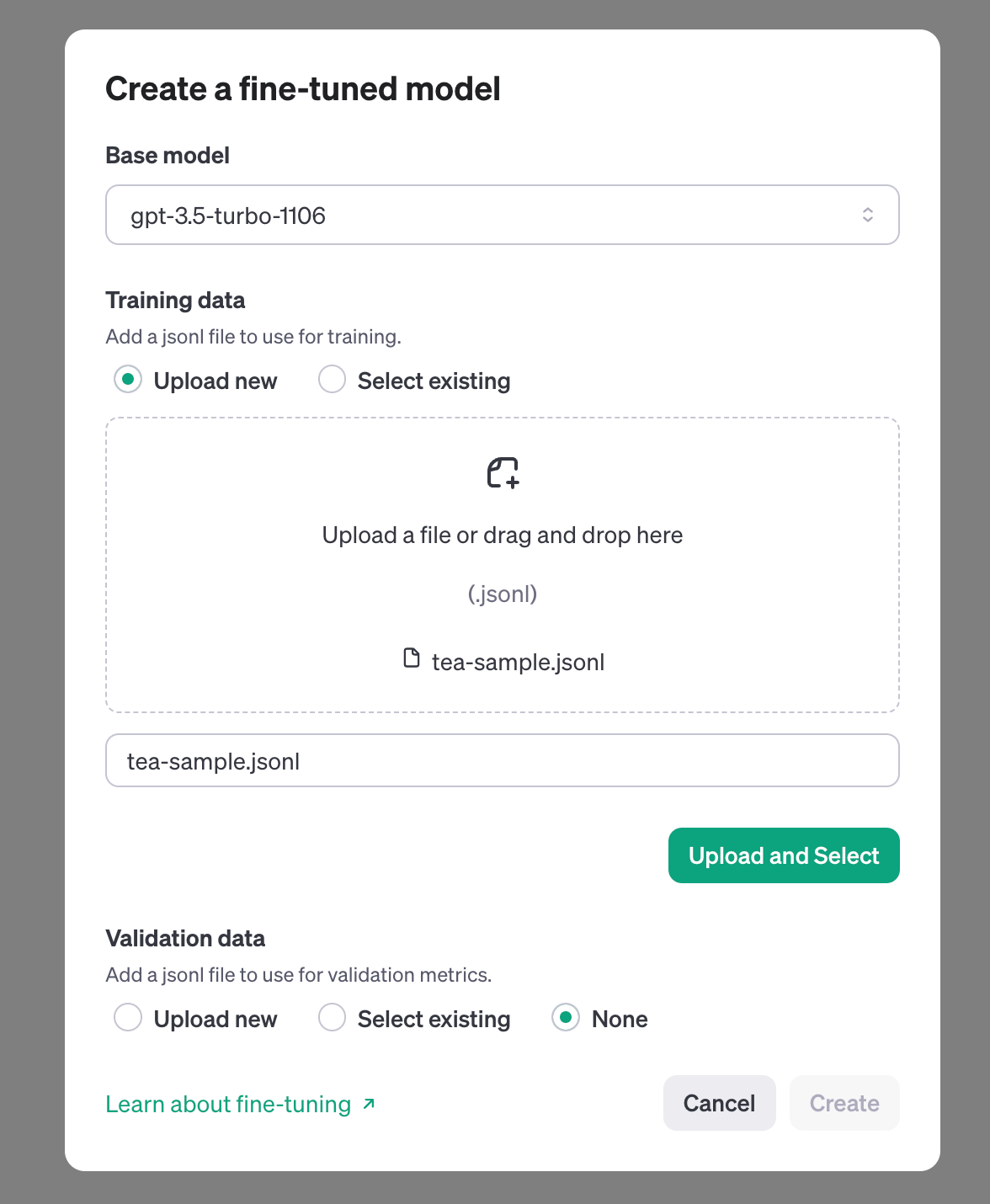
✨ Reminder: if your upload fails, it’s most likely because of a formatting issue. Use this JSON Lines Validator to confirm that your file is in the right format.
3. Wait for the training to complete
The training will take a few minutes, depending on how complex your fine-tuning data is. For the sample we are using, it only takes about 5 minutes for the training to finish.
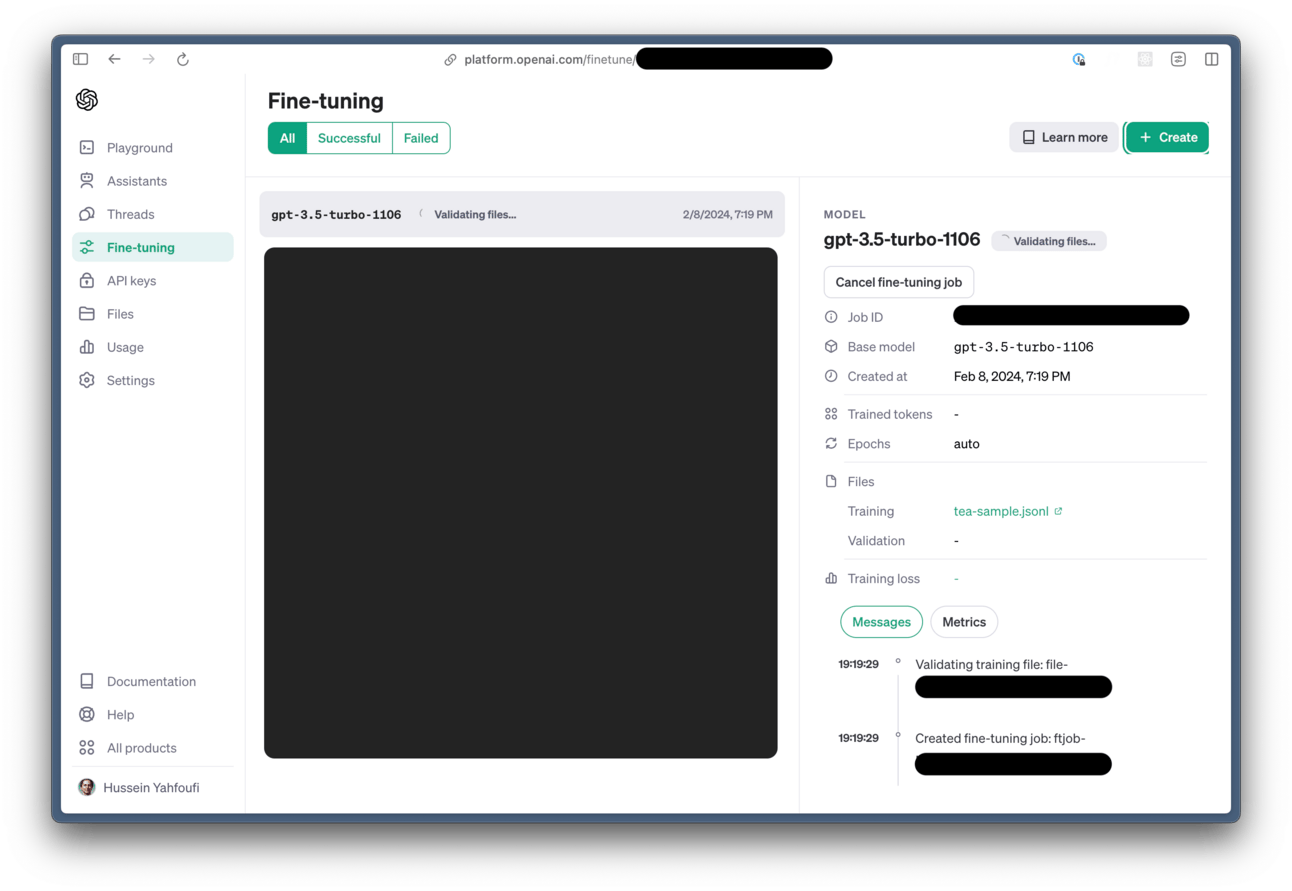
4. Use your new model!
Once the training is done, you can use the new model via the API or the Playground to test it out. In the Playground, it will now appear as one of your model options.
Enjoy!
What happens if your fine-tuned model does not work?
The first step is to add more examples 🙂 to your fine-tuning data. Ten records are the minimum for the upload to work, but this doesn’t mean the model will change after ten records. Even with the 50 that OpenAI says is the minimum, I don’t see much improvement. You really need to get to 100+ to start seeing good results.
After that, you can monitor results and change some of your sample data.
That’s all for today. Until next time!
— Hussein ✌️
P.S. If you enjoyed this email, please forward it to a friend. (Want rewards? 🎁 Use your custom link).
P.P.S. If you live in or visit San Diego, sign up here to be notified of tech and founder mixers I organize in the area. Would love to meet you there.
New around here? Join the newsletter (it's free).